
Manipulation de l'ordre de résolution des champs
L'objectif de la directive @export fournie par Exécution de requêtes multiples est d'exporter la valeur d'un champ (ou d'un ensemble de champs) dans une variable, pour l'utiliser ailleurs dans la requête.
Cette directive ne fonctionnerait pas si la lecture de la variable avait lieu avant l'exportation de la valeur dans cette variable. Par conséquent, le moteur doit fournir un moyen de contrôler l'ordre d'exécution des champs.
Gato GraphQL offre un moyen de manipuler l'ordre d'exécution des champs à travers la requête elle-même. Le moteur charge les données par itérations pour chaque type, en résolvant d'abord tous les champs du premier type qu'il rencontre dans la requête, puis tous les champs du deuxième type, et ainsi de suite jusqu'à ce qu'il n'y ait plus de types à traiter.
Par exemple, la requête suivante impliquant des objets de type Director, Film et Actor :
{
directors {
name
films {
title
actors {
name
}
}
}
}...est résolue par le moteur GraphQL dans cet ordre :

Si, après traitement, un type est à nouveau référencé dans la requête pour récupérer des données non chargées (par exemple : d'objets supplémentaires, ou de champs supplémentaires d'objets déjà chargés), alors le type est ajouté à nouveau à la fin de la liste d'itération.
Par exemple, si nous interrogeons également le champ preferredDirector de l'Actor (qui renvoie un objet de type Director) comme ceci :
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...alors le moteur GraphQL traite la requête dans cet ordre :

Voyons comment cela se déroule pour l'exécution de @export dans une seule requête. Pour notre première tentative, nous créons la requête comme nous le ferions normalement, sans penser à l'ordre d'exécution des champs :
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Lors de l'exécution de la requête, elle produit cette réponse :
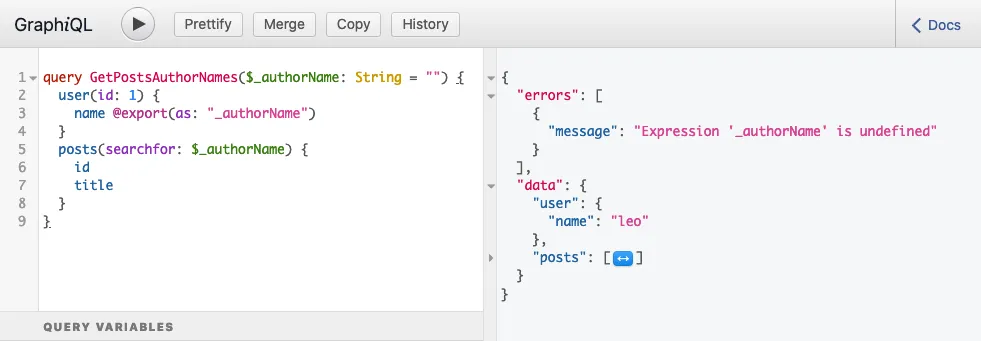
...qui contient l'erreur suivante :
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Cette erreur signifie que, au moment où la variable $authorName a été lue, elle n'avait pas encore été définie ; elle était undefined.
Voyons pourquoi cela se produit. Tout d'abord, analysons quels types apparaissent dans la requête, ajoutés sous forme de commentaires ci-dessous :
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Pour traiter les types et charger leurs données, le moteur de chargement de données ajoute le type de requête Root dans une liste FIFO (First-In, First-Out, « premier entré, premier sorti »), faisant ainsi de [Root] la liste initiale passée à l'algorithme, puis itère sur les types de manière séquentielle, comme suit :
| # | Opération | Liste |
|---|---|---|
| 0 | Préparer la liste FIFO | [Root] |
| 1a | Extraire le premier type de la liste (Root) | [] |
| 1b | Traiter tous les champs interrogés du type Root :→ user(by: {id: 1})→ posts(filter: { search: $authorName })Ajouter leurs types ( User et Post) à la liste | [User, Post] |
| 2a | Extraire le premier type de la liste (User) | [Post] |
| 2b | Traiter le champ interrogé du type User :→ name @export(as: "authorName")Comme c'est un type scalaire ( String), il n'est pas nécessaire de l'ajouter à la liste | [Post] |
| 3a | Extraire le premier type de la liste (Post) | [] |
| 3b | Traiter tous les champs interrogés du type Post :→ id→ titleComme ce sont des types scalaires ( ID et String), il n'est pas nécessaire de les ajouter à la liste | [] |
| 4 | La liste est vide, l'itération se termine. |
Nous pouvons voir ici le problème : @export est exécuté à l'étape 2b, mais il a été lu à l'étape 1b.
C'est ici que nous devons contrôler le flux d'exécution des champs. La solution implémentée consiste à retarder le moment où la variable exportée est lue, en interrogeant artificiellement le champ self du type Root.
Le champ self, comme son nom l'indique, renvoie le même objet ; appliqué à l'objet Root, il renvoie le même objet Root. Vous vous demandez peut-être : « si j'ai déjà l'objet racine, pourquoi aurais-je besoin de le récupérer à nouveau ? ». Parce que l'algorithme du moteur devra alors ajouter cette nouvelle référence à Root à la fin de la liste FIFO, et nous pouvons délibérément distribuer les champs interrogés avant ou après chacune de ces itérations.
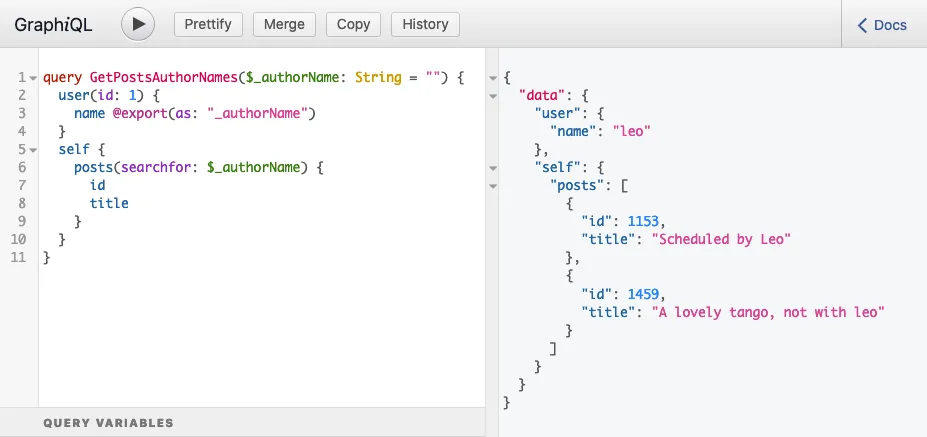
C'est pourquoi le champ posts(filter:{ search: $authorName }) est placé à l'intérieur d'un champ self dans la requête ci-dessus, et l'exécution de la requête produit la réponse attendue :
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Explorons l'ordre dans lequel les types sont traités pour cette requête, afin de comprendre pourquoi elle fonctionne correctement :
| # | Opération | Liste |
|---|---|---|
| 0 | Préparer la liste FIFO | [Root] |
| 1a | Extraire le premier type de la liste (Root) | [] |
| 1b | Traiter tous les champs interrogés du type Root :→ user(by: {id: 1})→ selfAjouter leurs types ( User et Root) à la liste | [User, Root] |
| 2a | Extraire le premier type de la liste (User) | [Root] |
| 2b | Traiter le champ interrogé du type User :→ name @export(as: "authorName")Comme c'est un type scalaire ( String), il n'est pas nécessaire de l'ajouter à la liste | [Root] |
| 3a | Extraire le premier type de la liste (Root) | [] |
| 3b | Traiter le champ interrogé du type Root :→ posts(filter:{ search: $authorName })Ajouter son type ( Post) à la liste | [Post] |
| 4a | Extraire le premier type de la liste (Post) | [] |
| 4b | Traiter tous les champs interrogés du type Post :→ id→ titleComme ce sont des types scalaires ( ID et String), il n'est pas nécessaire de les ajouter à la liste | [] |
| 5 | La liste est vide, l'itération se termine. |
Nous pouvons maintenant voir que le problème a été résolu : @export est exécuté à l'étape 2b, et il est lu à l'étape 3b.
Multiple Query Execution fait exactement cela lors du découplage des requêtes : il convertit le document GraphQL en ajoutant des champs self, afin que les champs de chaque opération ne soient exécutés qu'après que tous les champs de toutes les opérations précédentes ont été résolus.