
Pipeline de directives
Les directives sont placées dans un pipeline et exécutées dans l'ordre. Leur conception initiale est simple, comme ceci :

Dans cette architecture :
- L'entrée du pipeline est la valeur du champ fournie par le résolveur de champ
- Chaque directive exécute sa logique et transmet le résultat à la directive suivante dans le pipeline
- La sortie du pipeline sera la valeur du champ résolue, après avoir été traitée par toutes les directives
Cette architecture, cependant, ne tire pas le meilleur parti de GraphQL. Voici la description de toutes les étapes du pipeline de directives réel, jusqu'à atteindre la conception réellement implémentée dans Gato GraphQL.
Les directives comme blocs de construction de la résolution de la requête
Au départ, on pourrait envisager que le serveur GraphQL résolve le champ via un mécanisme quelconque, puis passe cette valeur comme entrée au pipeline de directives.
Cependant, il est bien plus simple d'avoir un seul mécanisme pour tout gérer : invoquer les résolveurs de champ (à la fois pour valider les champs et les résoudre) peut déjà être fait via le pipeline de directives. Dans ce cas, le pipeline de directives est le seul mécanisme utilisé pour résoudre la requête.
Pour cette raison, le serveur Gato GraphQL dispose de deux directives spéciales :
@validateappelle le résolveur de champ pour valider que le champ peut être résolu (ex. : la syntaxe est correcte, le champ existe, etc.)- En cas de succès,
@resolveValueAndMergeappelle ensuite le résolveur de champ pour résoudre le champ, et fusionne la valeur dans l'objet de réponse
Ces deux directives sont du type spécial « système » : elles sont réservées exclusivement au moteur GraphQL, et elles sont implicites sur chaque champ. (En revanche, les directives standard sont explicites : elles sont ajoutées à la requête par l'utilisateur.)
En utilisant ces deux directives, cette requête :
query {
field1
field2 @directiveA
}...sera résolue comme celle-ci :
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Le pipeline ressemble maintenant à ceci (remarquez que le pipeline reçoit le champ en entrée, et non sa valeur résolue initiale) :

Slots du pipeline
Les directives sont normalement exécutées après @resolveValueAndMerge, car elles impliquent le plus souvent une mise à jour de la valeur du champ résolu. Cependant, il existe d'autres directives qui doivent être exécutées avant @validate, ou entre @validate et @resolveValueAndMerge.
Par exemple :
- Pour mesurer le temps nécessaire à la résolution d'un champ, la directive
@traceExecutionTimepeut obtenir l'heure courante avant et après la résolution du champ, en plaçant les sous-directives@startTracingExecutionTimeau début et@endTracingExecutionTimeà la fin du pipeline - Une directive
@cachedoit vérifier si un champ demandé est en cache et retourner cette réponse directement, avant d'exécuter@resolveValueAndMerge
Le pipeline offrira alors cinq slots différents via la classe PipelinePositions, et la directive indiquera dans lequel elle doit être exécutée :
- Le slot
"beginning": tout au début - Le slot
"before-validate": avant que la validation ait lieu - Le slot
"middle": après la validation et avant la résolution du champ - Le slot
"after-resolve": après la résolution du champ - Le slot
"end": tout à la fin
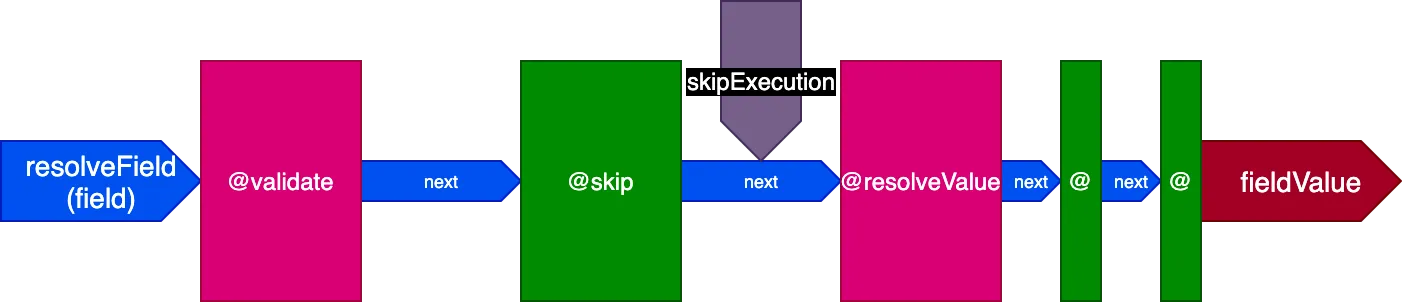
Le pipeline de directives ressemble maintenant à ceci (en considérant seulement 3 étapes, par souci de simplification) :

Remarquez comment les directives @skip et @include peuvent être facilement satisfaites avec cette architecture : placées dans le slot "middle", elles peuvent informer la directive @resolveValueAndMerge (ainsi que toutes les directives aux étapes ultérieures du pipeline) de ne pas s'exécuter en définissant le flag skipExecution à true.
Exécuter la directive sur plusieurs champs en un seul appel
Jusqu'à présent, nous avons considéré un seul champ comme entrée du pipeline de directives. Cependant, dans une requête GraphQL typique, nous recevrons plusieurs champs sur lesquels exécuter des directives.
Par exemple, dans la requête ci-dessous, la directive @upperCase est exécutée sur les champs "field1" et "field2" :
query {
field1 @upperCase
field2 @upperCase
field3
}De plus, puisque le moteur GraphQL ajoute les directives système @validate et @resolveValueAndMerge à chaque champ de la requête, de sorte que cette requête :
query {
field1
field2
field3
}...est résolue comme cette requête :
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Alors, les directives système recevront toujours tous les champs en entrée.
En conséquence, le pipeline de directives est conçu pour recevoir plusieurs champs en entrée, et pas seulement un à la fois :

Cette architecture est plus efficace, car exécuter une directive une seule fois pour tous les champs est plus rapide que de l'exécuter une fois par champ, et produira les mêmes résultats.
Par exemple, lors de la validation que l'utilisateur est connecté pour lui accorder l'accès au schéma, l'opération peut être exécutée une seule fois. Exécuter le code suivant :
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}est plus efficace que d'exécuter ce code :
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Cela peut ne pas sembler être un problème majeur lors de l'appel d'une fonction locale comme isUserLoggedIn, cependant cela peut faire une grande différence lors de l'interaction avec des services externes, comme lors de la résolution d'endpoints REST via GraphQL. Dans ces cas, exécuter une fonction une seule fois au lieu de plusieurs fois pourrait faire la différence entre pouvoir fournir une certaine fonctionnalité ou non.
Voyons un exemple. Lors de l'interaction avec Google Translate via une directive @translate, l'API GraphQL doit établir une connexion sur le réseau. Exécuter ce code sera aussi rapide que possible :
googleTranslateFields([$field1, $field2, $field3]);En revanche, exécuter la fonction séparément, plusieurs fois, produira une latence plus élevée qui se traduira par un temps de réponse plus long, dégradant les performances de l'API. Ce n'est peut-être pas une grande différence pour traduire 3 chaînes (où le champ est la chaîne à traduire), mais pour 100 chaînes ou plus, cela aura certainement un impact :
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);De plus, exécuter une fonction une seule fois avec toutes les entrées peut produire une meilleure réponse qu'en exécutant la fonction sur chaque champ indépendamment. En reprenant l'exemple de Google Translate, la traduction sera plus précise plus nous fournissons de données au service.
Par exemple, lors de l'exécution du code ci-dessous :
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Pour la première exécution indépendante, Google ne connaît pas le contexte de "fork", et peut donc répondre avec fork comme ustensile de cuisine, comme une bifurcation de route, ou avec une autre signification. Cependant, si nous exécutons à la place :
googleTranslate(["fork", "road", "sign"]);À partir de cette plus grande quantité d'informations, Google peut déduire que "fork" fait référence à la bifurcation de la route, et retourner une traduction précise.
C'est pour ces raisons que les directives dans le pipeline reçoivent les champs d'entrée tous ensemble, et chaque directive peut ensuite décider de la meilleure façon d'exécuter sa logique sur ces entrées (une seule exécution par entrée, une seule exécution comprenant toutes les entrées, ou n'importe quoi entre les deux).
Le pipeline ressemble maintenant à ceci :
Exécuter un seul pipeline de directives pour toute la requête
Nous venons de voir qu'il est logique d'exécuter plusieurs champs par directive, mais cela fonctionne bien tant que tous les champs ont les mêmes directives appliquées. Lorsque les directives sont différentes, cela peut entraîner une complexité accrue qui rend son implémentation difficile et réduirait certains des bénéfices obtenus.
Voyons comment cela se produit. Considérons la requête suivante :
query {
field1 @directiveA
field2
field3
}Cette directive est équivalente à celle-ci :
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Dans ce scénario, les champs field2 et field3 ont le même ensemble de directives, et field1 en a un différent ; nous devrions donc générer 2 pipelines différents pour résoudre la requête :
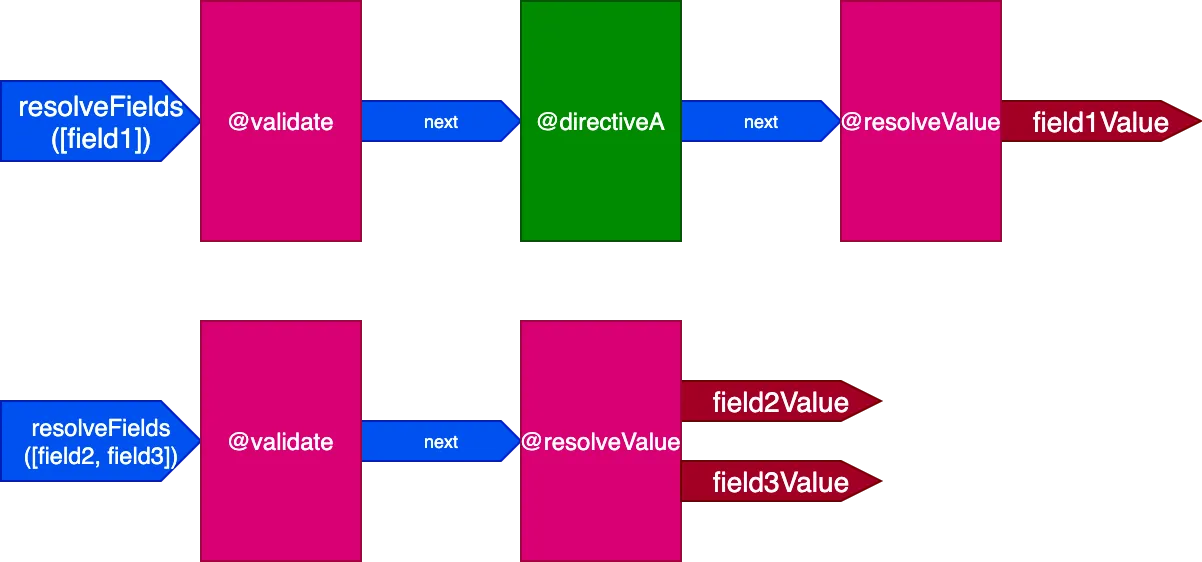
Et lorsque tous les champs ont un ensemble unique de directives, l'effet est encore plus prononcé. Considérons cette requête :
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Ce qui est équivalent à ceci :
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}Dans cette situation, nous aurons 3 pipelines pour gérer 3 champs, comme ceci :
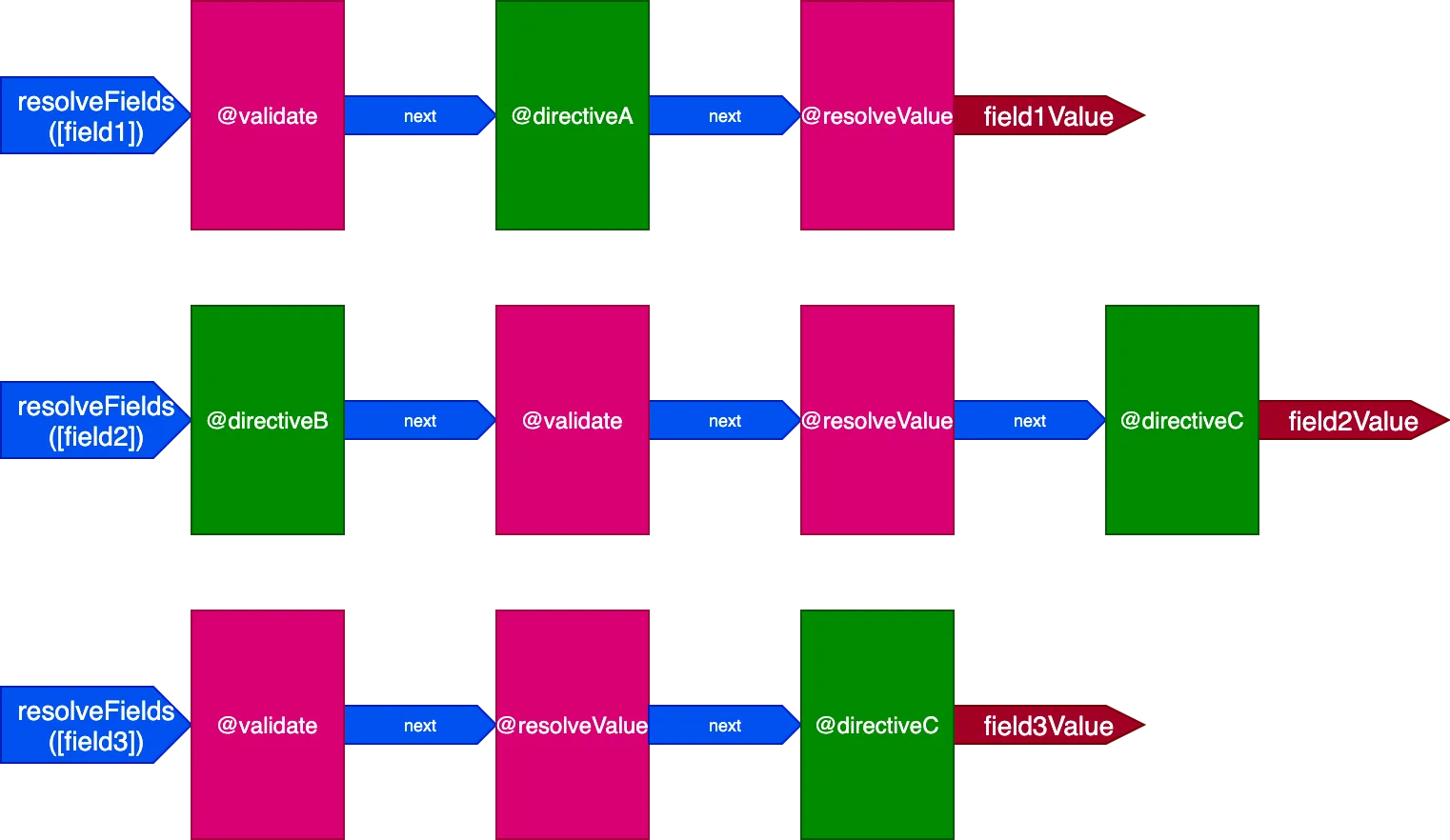
Dans ce cas, même si les directives @validate et @resolveValueAndMerge sont appliquées aux 3 champs, puisqu'elles sont exécutées via 3 pipelines de directives différents, elles seront exécutées indépendamment les unes des autres, ce qui nous ramène à avoir une directive exécutée sur un seul élément à la fois.
La solution à ce problème est d'éviter de produire plusieurs pipelines, mais de travailler avec un seul pipeline pour tous les champs. En conséquence, le moteur ne passe plus les champs comme entrée au pipeline, car toutes les directives d'un seul pipeline n'interagiront pas avec le même ensemble de champs ; à la place, chaque directive doit recevoir sa propre liste de champs comme entrée.
Alors, pour cette requête :
query {
field1 @directiveA
field2
field3
}...les directives @validate et @resolveValueAndMerge recevront les 3 champs en entrée, et directiveA ne recevra que "field1" :
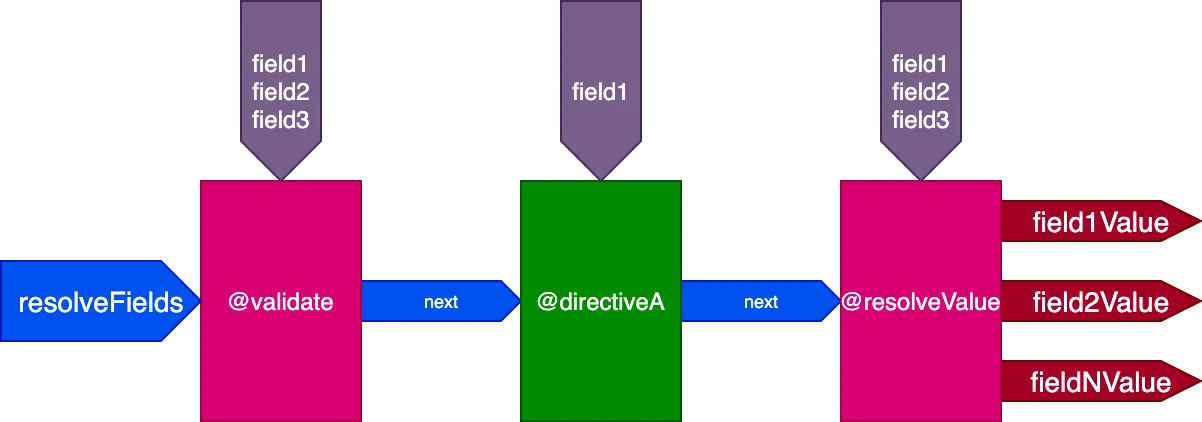
Et pour cette requête :
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...les directives @validate et @resolveValueAndMerge recevront les 3 champs en entrée, directiveA ne recevra que "field1", directiveB ne recevra que "field2", et directiveC recevra "field2" et "field3" :
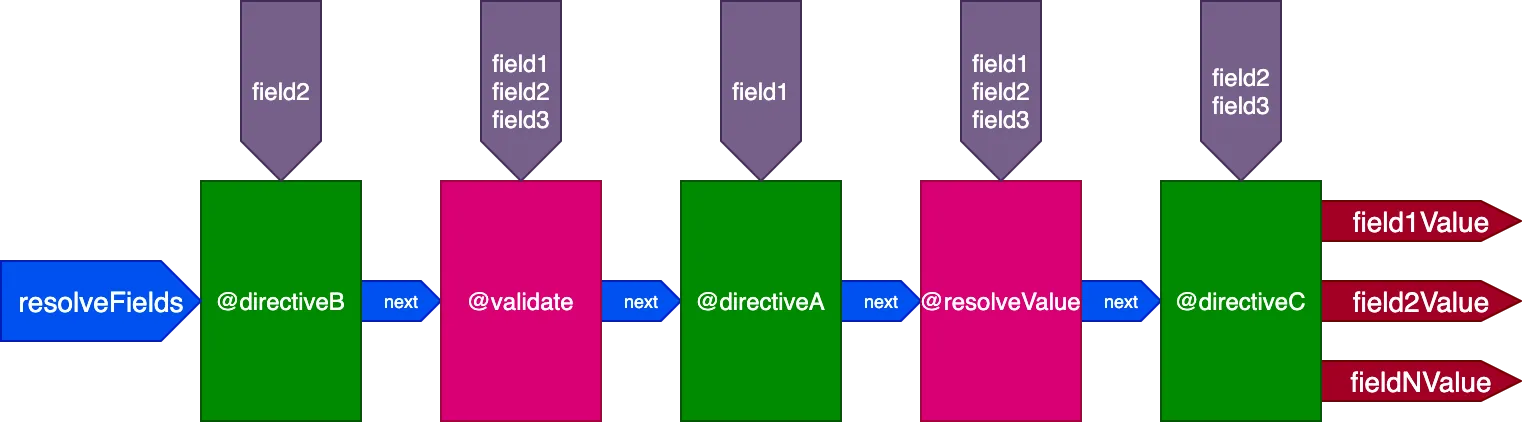
Contrôle de l'exécution de la directive identifiant par identifiant
Jusqu'à présent, une directive à une certaine étape pouvait influencer l'exécution des directives aux étapes ultérieures via un flag skipExecution. Cependant, ce flag n'est pas suffisamment granulaire pour tous les cas.
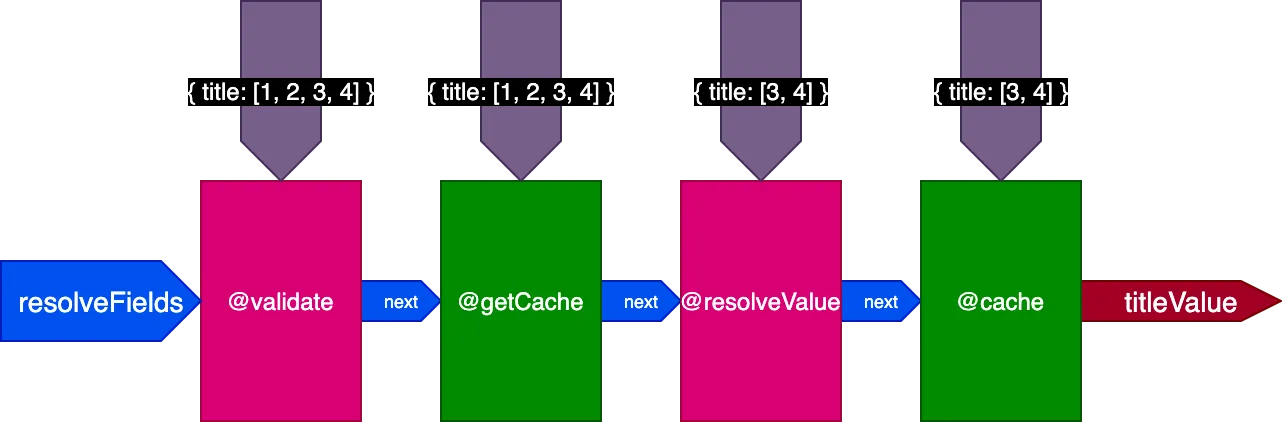
Par exemple, considérons une directive @cache, placée dans le slot "end" pour stocker la valeur du champ, de sorte que la prochaine fois que le champ est interrogé, sa valeur puisse être récupérée depuis le cache via une directive @getCache placée dans le slot "middle" :
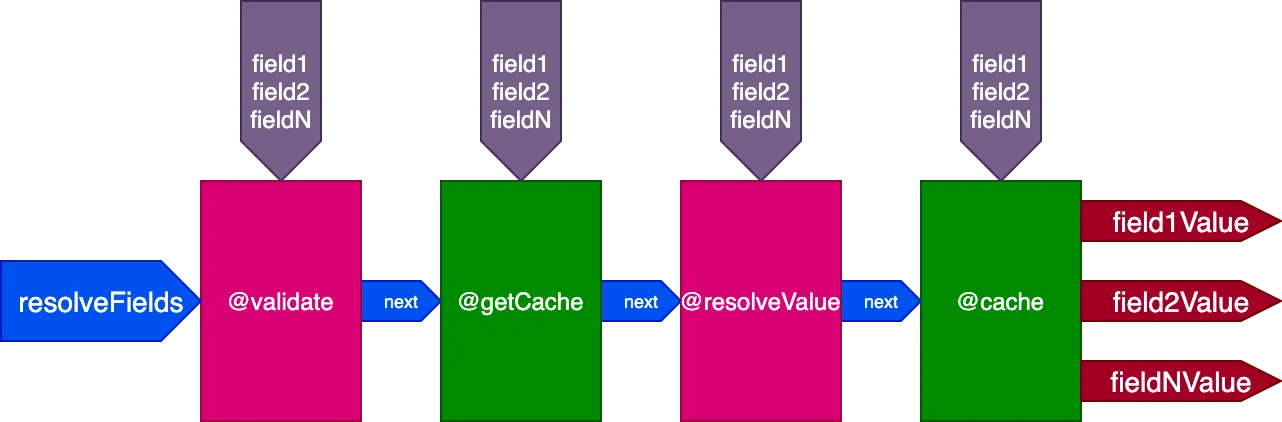
Lors de l'exécution de cette requête :
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Le serveur récupérera et mettra en cache 2 enregistrements. Ensuite, nous exécutons la même requête, mais appliquée à 4 enregistrements :
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Lors de l'exécution de cette 2ème requête, les 2 enregistrements de la 1ère requête étaient déjà en cache, mais les 2 autres ne l'étaient pas. Cependant, nous aurions besoin que les 4 enregistrements soient déjà en cache pour utiliser le flag skipExecution. Il serait préférable de pouvoir récupérer les 2 premiers enregistrements depuis le cache, et ne résoudre que les 2 autres enregistrements.
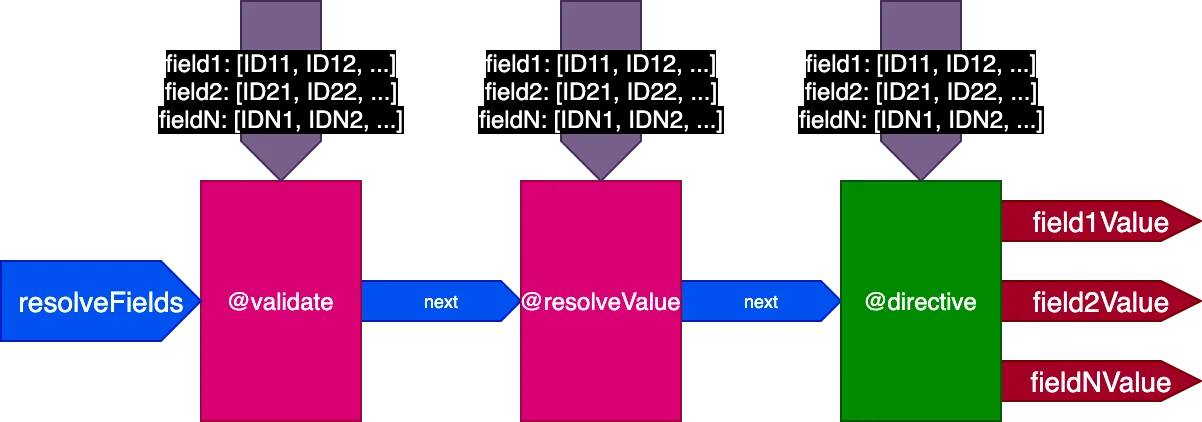
Nous mettons donc à jour la conception du pipeline. Nous abandonnons le flag skipExecution, et à la place nous passons à chaque directive la liste des identifiants d'objets par champ sur lesquels la directive doit être appliquée, via un objet d'entrée fieldIDs :
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}La variable fieldIDs est unique à chaque directive, et chaque directive peut modifier l'instance de fieldIDs pour toutes les directives aux étapes ultérieures. Ainsi, skipExecution peut être effectué de manière granulaire, identifiant par identifiant, en supprimant simplement l'identifiant de fieldIDs pour toutes les directives suivantes dans la pile.
Le pipeline ressemble maintenant à ceci :
Appliqué à l'exemple précédent, lors de l'exécution de la première requête en traduisant 2 enregistrements, le pipeline ressemble à ceci :
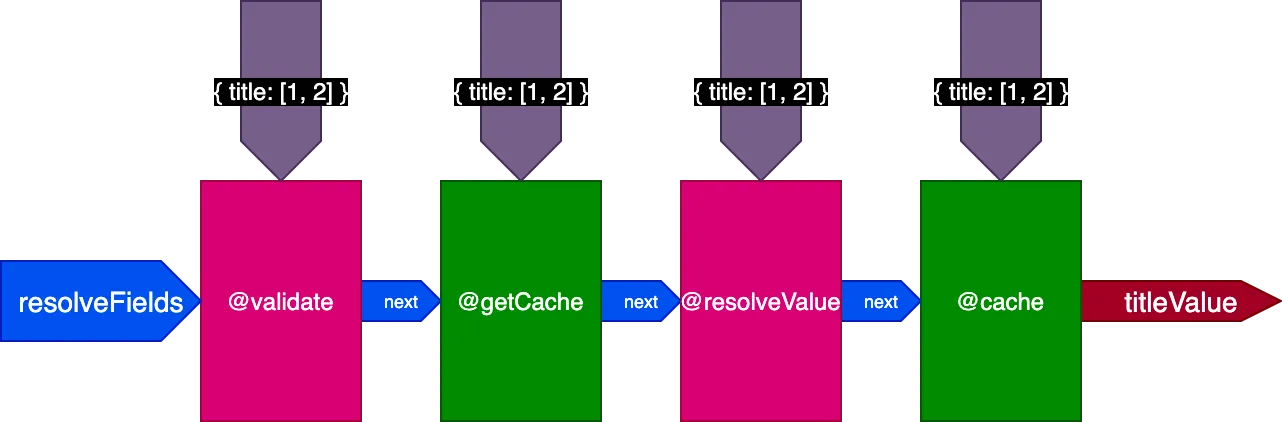
Lors de l'exécution de la deuxième requête en traduisant 4 enregistrements, la directive @getCache reçoit les identifiants des 4 enregistrements, mais @resolveValueAndMerge et @cache ne recevront que les identifiants des 2 derniers enregistrements (qui ne sont pas en cache) :
Tout assembler
Voici la conception finale du pipeline de directives :
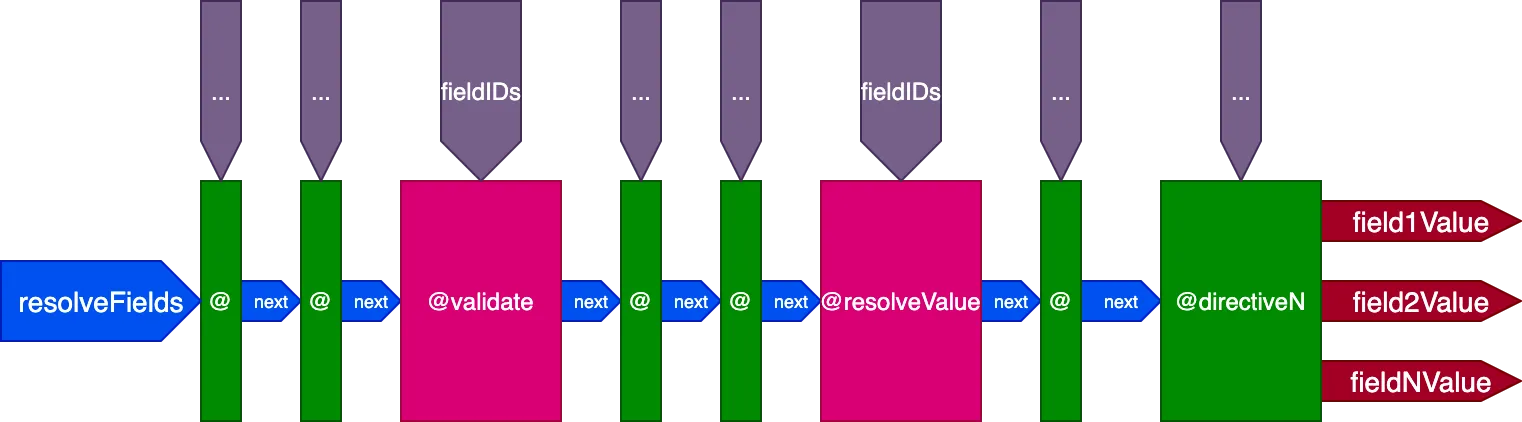
En résumé, voici ses caractéristiques :
- Les résolveurs de champ sont invoqués depuis le pipeline de directives lui-même, via les directives
@validateet@resolveValueAndMerge - Les directives peuvent être placées dans l'un des 5 slots :
"beginning","before-validate","middle","after-validate"et"end" - Les directives résolvent plusieurs champs en un seul appel
- Un seul pipeline contient toutes les directives impliquées dans la requête
- Chaque directive reçoit son propre ensemble d'identifiants à résoudre par champ via la variable
fieldIDs - Les directives peuvent modifier la variable
fieldIDspour toutes les directives à une étape ultérieure du pipeline