
Moteur de chargement des données
Gato GraphQL utilise des composants côté serveur pour représenter le modèle de données (pas des graphes ni des arbres). Voyons comment il exécute le processus de chargement des données pour résoudre la requête GraphQL.
Pour traiter les données, nous devons aplatir les composants en types (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), les ordonner selon leur apparition dans la hiérarchie des composants (Director, puis Film, puis Actor) et les traiter par « itérations », en récupérant les données des objets pour chaque type lors de sa propre itération, ainsi :

Le moteur de chargement des données du serveur doit implémenter le (pseudo-)algorithme suivant pour charger les données :
Préparation :
- Préparer une file d'attente vide pour stocker la liste des identifiants des objets à récupérer depuis la base de données, organisés par type (chaque entrée sera :
[type => liste d'identifiants]) - Récupérer l'identifiant de l'objet directeur mis en avant et le placer dans la file d'attente sous le type
Director
Boucle jusqu'à ce qu'il n'y ait plus d'entrées dans la file d'attente :
- Obtenir la première entrée de la file d'attente : le type et la liste des identifiants (ex. :
Directoret[2]), puis retirer cette entrée de la file d'attente - En utilisant l'objet
TypeDataLoaderdu type, exécuter une seule requête contre la base de données pour récupérer tous les objets de ce type avec ces identifiants - Si le type possède des champs relationnels (ex. : le type
Directorpossède le champ relationnelfilmsde typeFilm), alors collecter tous les identifiants de ces champs depuis tous les objets récupérés lors de l'itération courante (ex. : tous les identifiants du champfilmsde tous les objets de typeDirector), et placer ces identifiants dans la file d'attente sous le type correspondant (ex. : les identifiants[3, 8]sous le typeFilm).
À la fin des itérations, nous aurons chargé toutes les données des objets pour tous les types, ainsi :
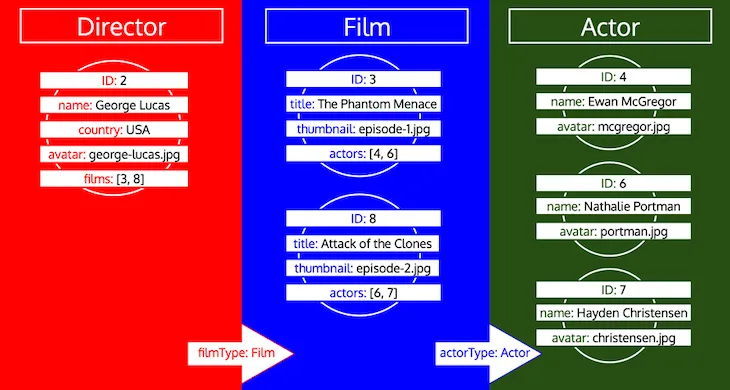
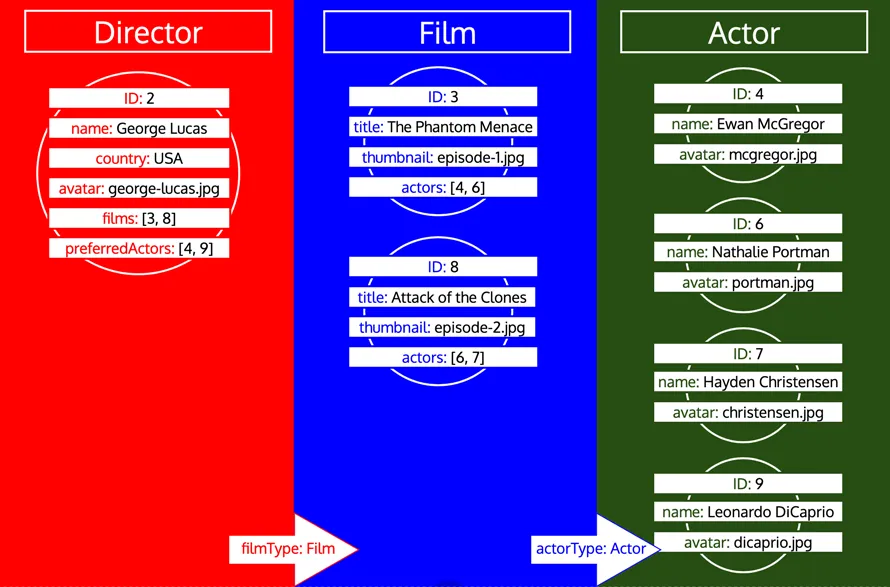
Remarquez comment tous les identifiants d'un type sont collectés jusqu'à ce que ce type soit traité dans la file d'attente. Si, par exemple, nous ajoutons un champ relationnel preferredActors au type Director, ces identifiants seraient ajoutés à la file d'attente sous le type Actor, et seraient traités en même temps que les identifiants du champ actors du type Film :
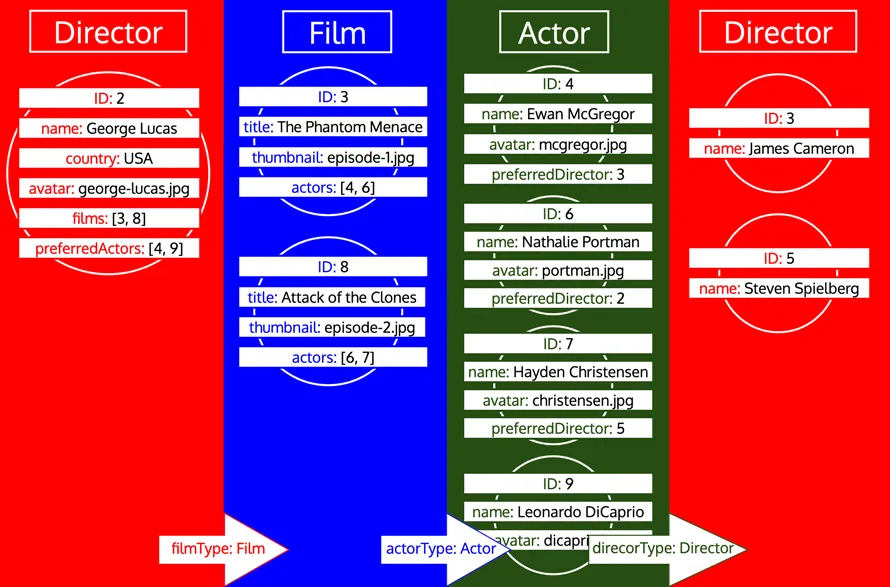
Cependant, si un type a déjà été traité et qu'il faut ensuite charger davantage de données de ce type, il s'agit d'une nouvelle itération sur ce type. Par exemple, ajouter un champ relationnel preferredDirector au type Author fera que le type Director sera ajouté de nouveau à la file d'attente :
Maintenant que nous avons récupéré toutes les données des objets, nous devons leur donner la forme de la réponse attendue, en reflétant la requête GraphQL. Cependant, comme on peut le constater, les données n'ont pas la structure d'arbre requise. Au lieu de cela, les champs relationnels contiennent les identifiants de l'objet imbriqué, imitant la façon dont les données sont représentées dans une base de données relationnelle. Ainsi, en suivant cette comparaison, les données récupérées pour chaque type peuvent être représentées sous forme de tableau, ainsi :
Tableau pour le type Director :
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tableau pour le type Film :
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tableau pour le type Actor :
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Avec toutes les données organisées en tableaux, et en sachant comment chaque type est lié aux autres (c'est-à-dire que Director référence Film via le champ films, Film référence Actor via le champ actors), le serveur GraphQL peut facilement convertir les données en la structure d'arbre attendue :
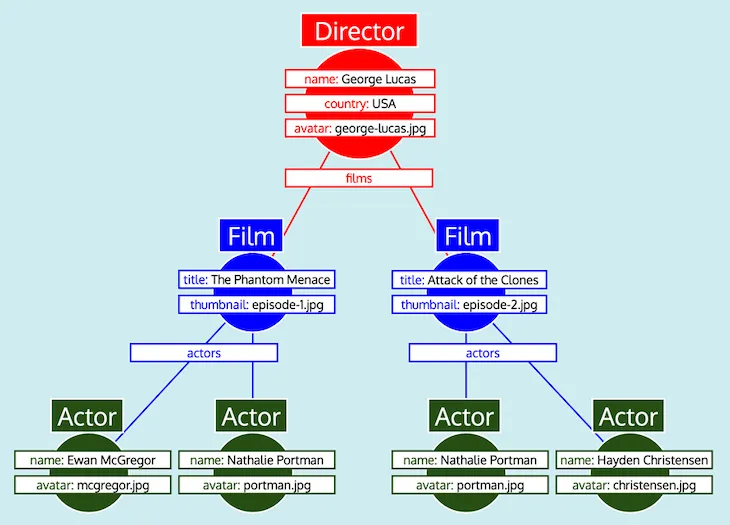
Enfin, le serveur GraphQL émet l'arbre, qui a la forme de la réponse attendue :
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analyse de la complexité temporelle de la solution
Analysons la notation Grand O de l'algorithme de chargement des données pour comprendre comment le nombre de requêtes exécutées contre la base de données croît à mesure que le nombre d'entrées augmente, afin de s'assurer que cette solution est performante.
Le moteur de chargement des données charge les données en itérations correspondant à chaque type. Au moment où il démarre une itération, il dispose déjà de la liste de tous les identifiants de tous les objets à récupérer, et peut donc exécuter une seule requête pour récupérer toutes les données des objets correspondants. Il s'ensuit que le nombre de requêtes vers la base de données croîtra de manière linéaire avec le nombre de types impliqués dans la requête. En d'autres termes, la complexité temporelle est O(n), où n est le nombre de types dans la requête (cependant, si un type est itéré plus d'une fois, il doit être comptabilisé plus d'une fois dans n).
Cette solution est très performante, bien meilleure que la complexité exponentielle attendue lors du traitement de graphes, ou la complexité logarithmique attendue lors du traitement d'arbres.
Code PHP implémenté
Le processus de chargement des données se déroule dans la fonction getComponentData de la classe Engine du paquet Component Model.