Persisted Queries
Utilisez des requêtes GraphQL pour créer des endpoints prédéfinis comme en REST, en obtenant les avantages des deux APIs.
Description
Avec REST, vous créez plusieurs endpoints, chacun retournant un ensemble prédéfini de données.
| Avantages | Inconvénients |
|---|---|
| ✅ C'est simple | ❌ C'est fastidieux de créer tous les endpoints |
✅ Accessible via GET ou POST | ❌ Un projet peut faire face à des goulots d'étranglement en attendant que les endpoints soient prêts |
| ✅ Peut être mis en cache sur le serveur ou le CDN | ❌ Produire de la documentation est obligatoire |
| ✅ C'est sécurisé : seules les données prévues sont exposées | ❌ Peut être lent (principalement pour les applications mobiles), car l'application peut nécessiter plusieurs requêtes pour récupérer toutes les données |
Avec GraphQL, vous fournissez n'importe quelle requête à un seul endpoint, qui retourne exactement les données demandées.
| Avantages | Inconvénients |
|---|---|
| ✅ Pas de sous/sur-récupération de données | ❌ Accessible uniquement via POST |
| ✅ Peut être rapide, car toutes les données sont récupérées en une seule requête | ❌ Ne peut pas être mis en cache sur le serveur ou le CDN, ce qui le rend plus lent et plus coûteux |
| ✅ Permet une itération rapide du projet | ❌ Peut nécessiter de réinventer la roue, comme pour l'upload de fichiers ou la mise en cache |
| ✅ Peut être auto-documenté | ❌ Doit faire face à des complexités supplémentaires, comme le problème N+1 |
| ✅ Fournit un éditeur pour la requête (GraphiQL) qui simplifie la tâche |
Les persisted queries combinent ces 2 approches :
- Elles utilisent GraphQL pour créer et résoudre des requêtes
- Mais au lieu d'exposer un seul endpoint, elles exposent chaque requête prédéfinie sous son propre endpoint
Ainsi, on obtient plusieurs endpoints avec des données prédéfinies, comme en REST, mais créés à l'aide de GraphQL, en obtenant les avantages de chacun et en évitant leurs inconvénients :
| Avantages | Inconvénients |
|---|---|
✅ Accessible via GET ou POST | |
| ✅ Peut être mis en cache sur le serveur ou le CDN | |
| ✅ C'est sécurisé : seules les données prévues sont exposées | |
| ✅ Pas de sous/sur-récupération de données | |
| ✅ Peut être rapide, car toutes les données sont récupérées en une seule requête | POST |
| ✅ Permet une itération rapide du projet | |
| ✅ Peut être auto-documenté | |
| ✅ Fournit un éditeur pour la requête (GraphiQL) qui simplifie la tâche |

Exécution de la Persisted Query
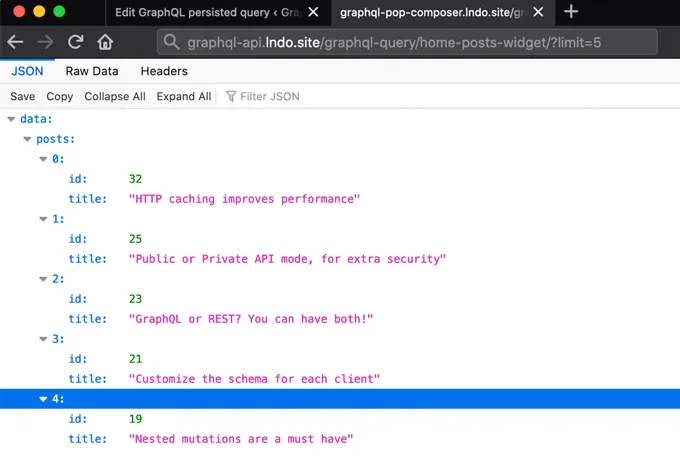
Une fois la persisted query publiée, nous pouvons l'exécuter via son permalien.
La persisted query peut être exécutée directement dans le navigateur, car elle est accessible via GET, et nous obtiendrons les données demandées au format JSON :
Création d'une Persisted Query
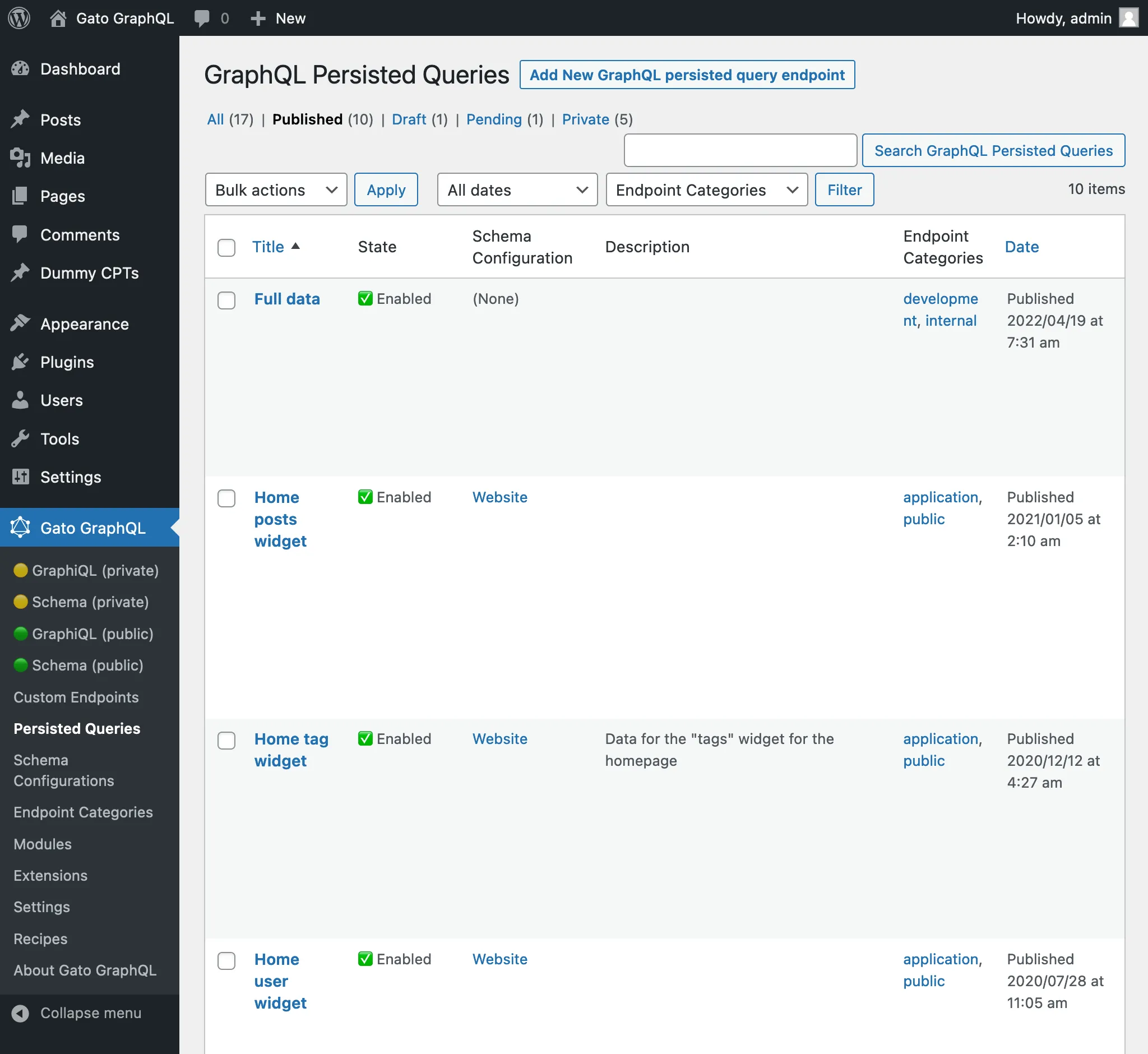
En cliquant sur le lien Persisted Queries dans le menu, la liste de toutes les persisted queries créées s'affiche :
Une persisted query est un custom post type (CPT). Pour créer une nouvelle persisted query, cliquez sur le bouton "Ajouter une nouvelle persisted query GraphQL", ce qui ouvrira l'éditeur WordPress :
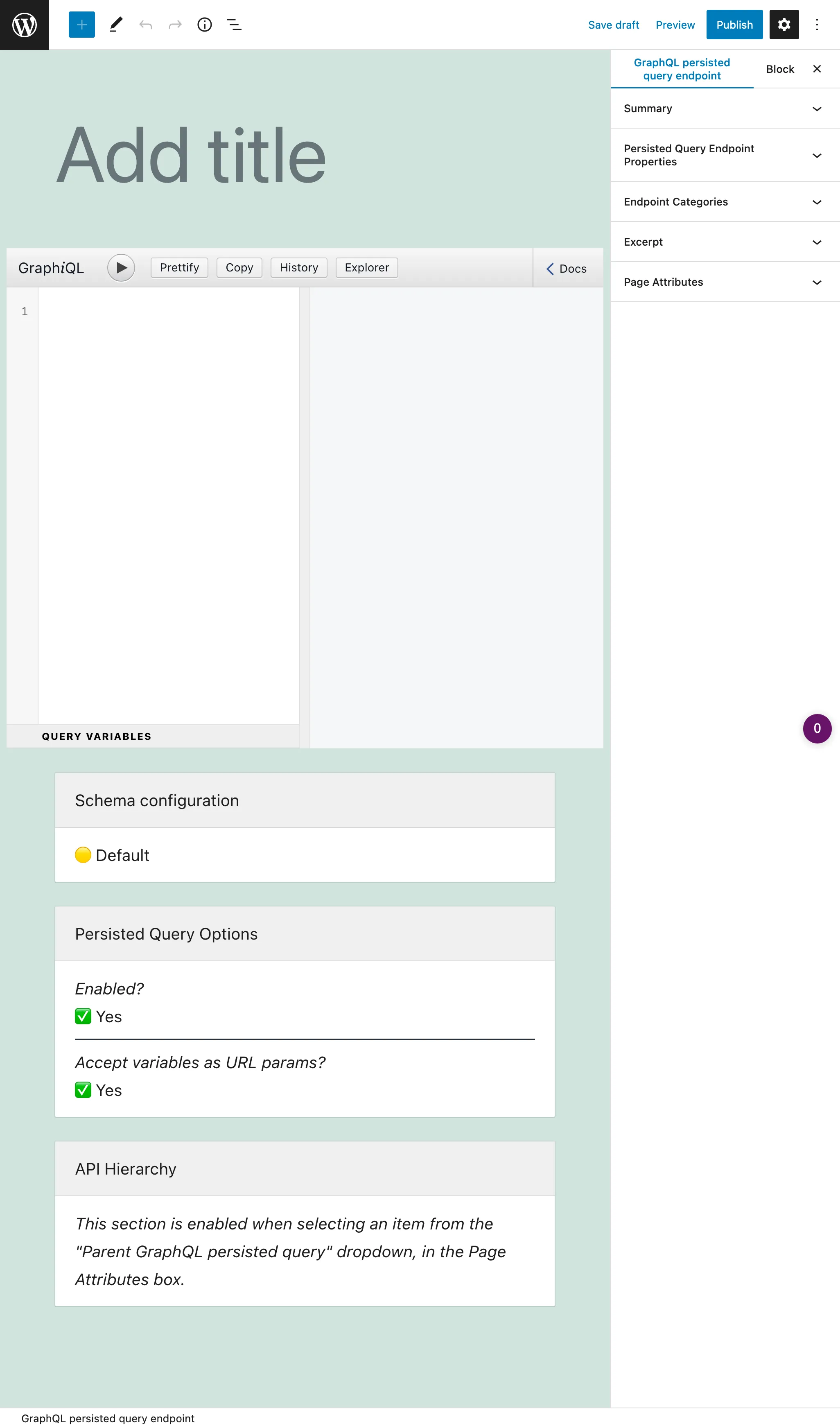
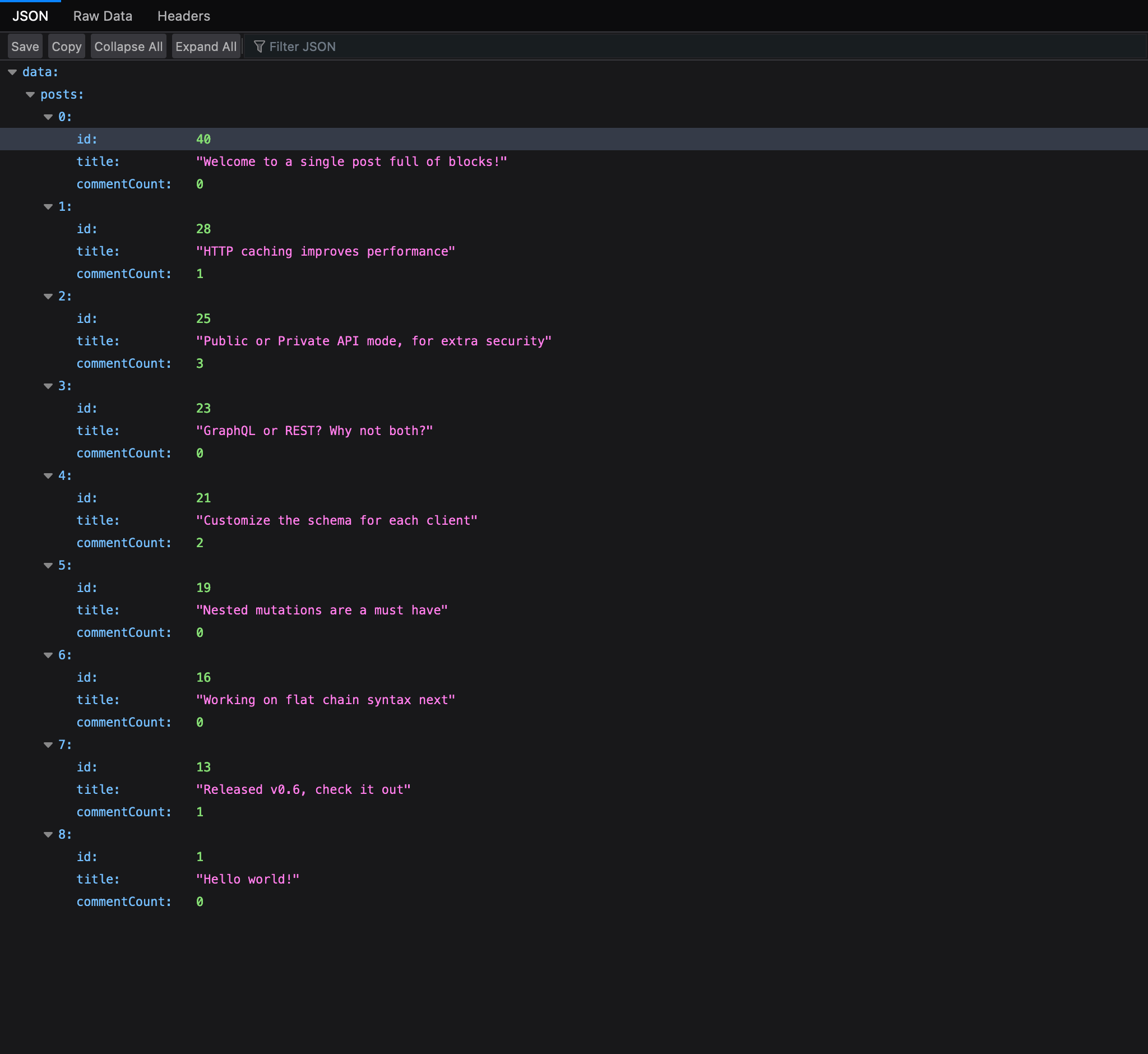
La saisie principale est le client GraphiQL, qui est fourni avec l'Explorer par défaut. Cliquer sur les champs dans le panneau latéral gauche les ajoute à la requête, et cliquer sur le bouton "Run" exécute la requête :

Lorsque la requête est prête, publiez-la, et son permalien devient son endpoint. Le lien vers l'endpoint (et vers la source) est affiché dans le panneau latéral "Aperçu de l'Endpoint de Persisted Query" :
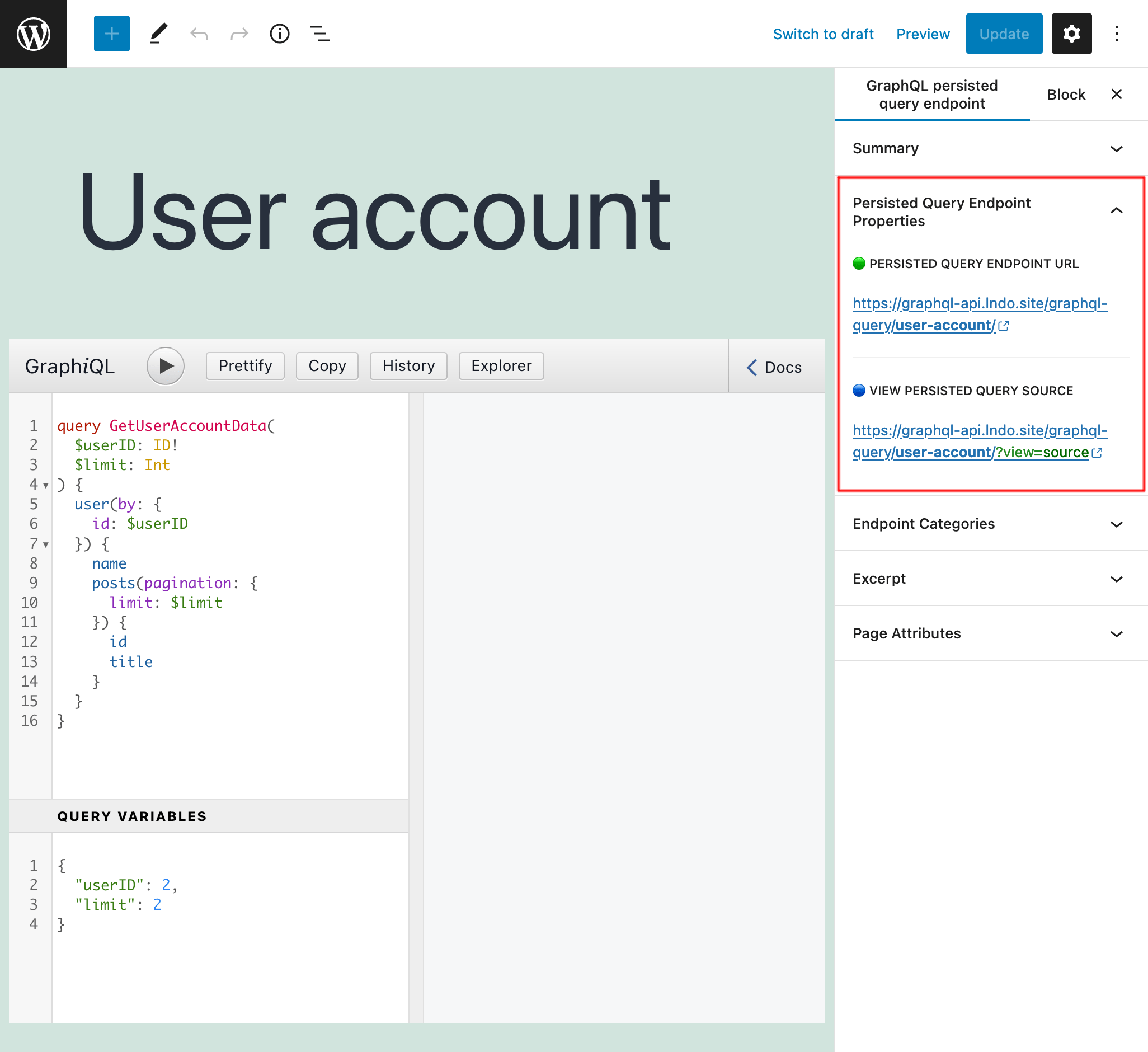
En ajoutant ?view=source au permalien, la persisted query et sa configuration s'afficheront (à condition que l'utilisateur soit connecté et que son rôle ait accès) :

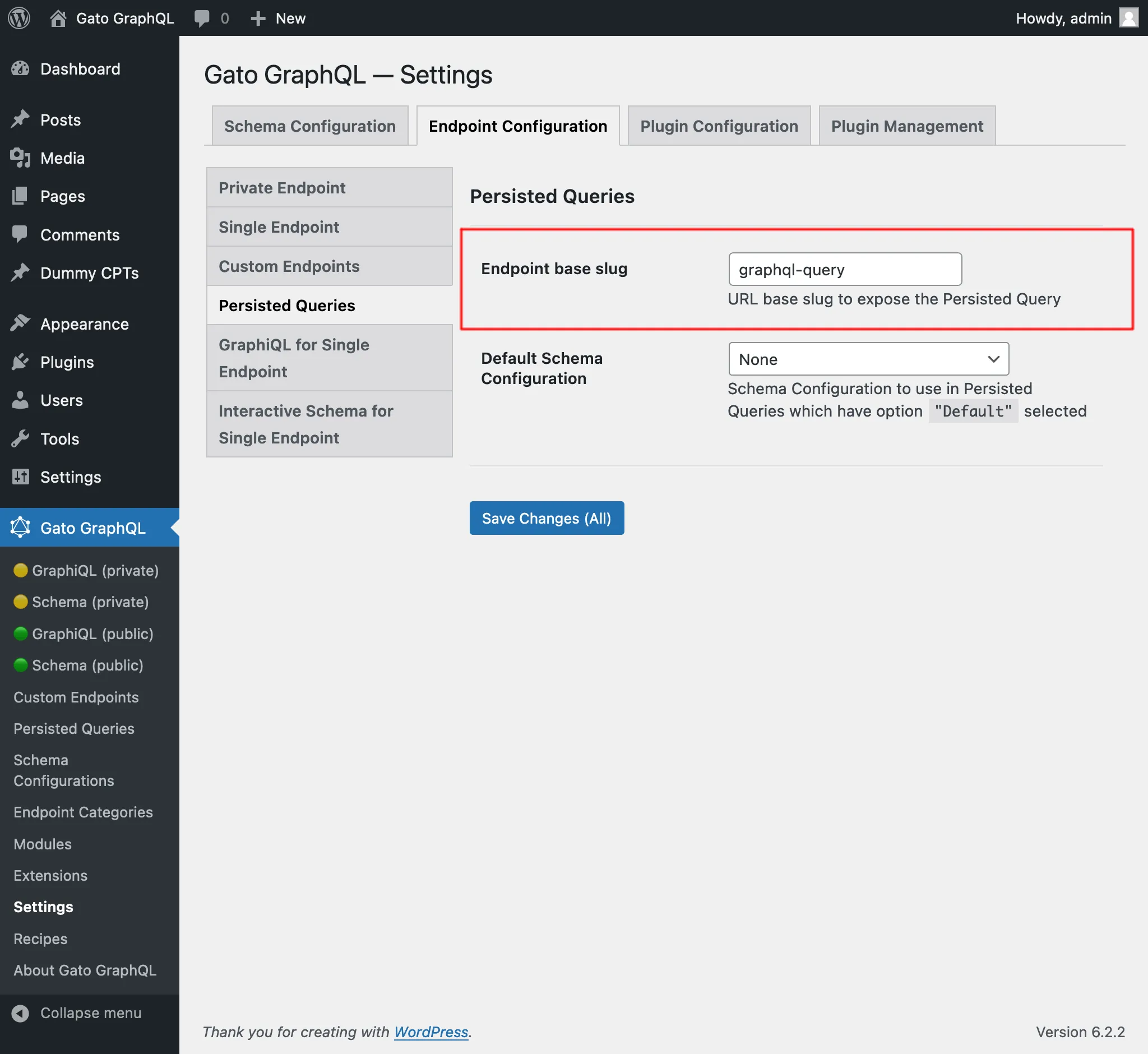
Par défaut, l'endpoint de la persisted query a le chemin /graphql-query/, et cette valeur est configurable via les Paramètres :
Configuration du schéma
La définition des éléments que contient le schéma, et de l'accès que les utilisateurs y auront, est définie dans la configuration du schéma.
Nous devons donc créer une configuration du schéma, puis la sélectionner dans le menu déroulant :

Organisation des Persisted Queries par catégorie
Dans le panneau latéral "Catégories d'endpoint", nous pouvons ajouter des catégories pour aider à gérer la Persisted Query :
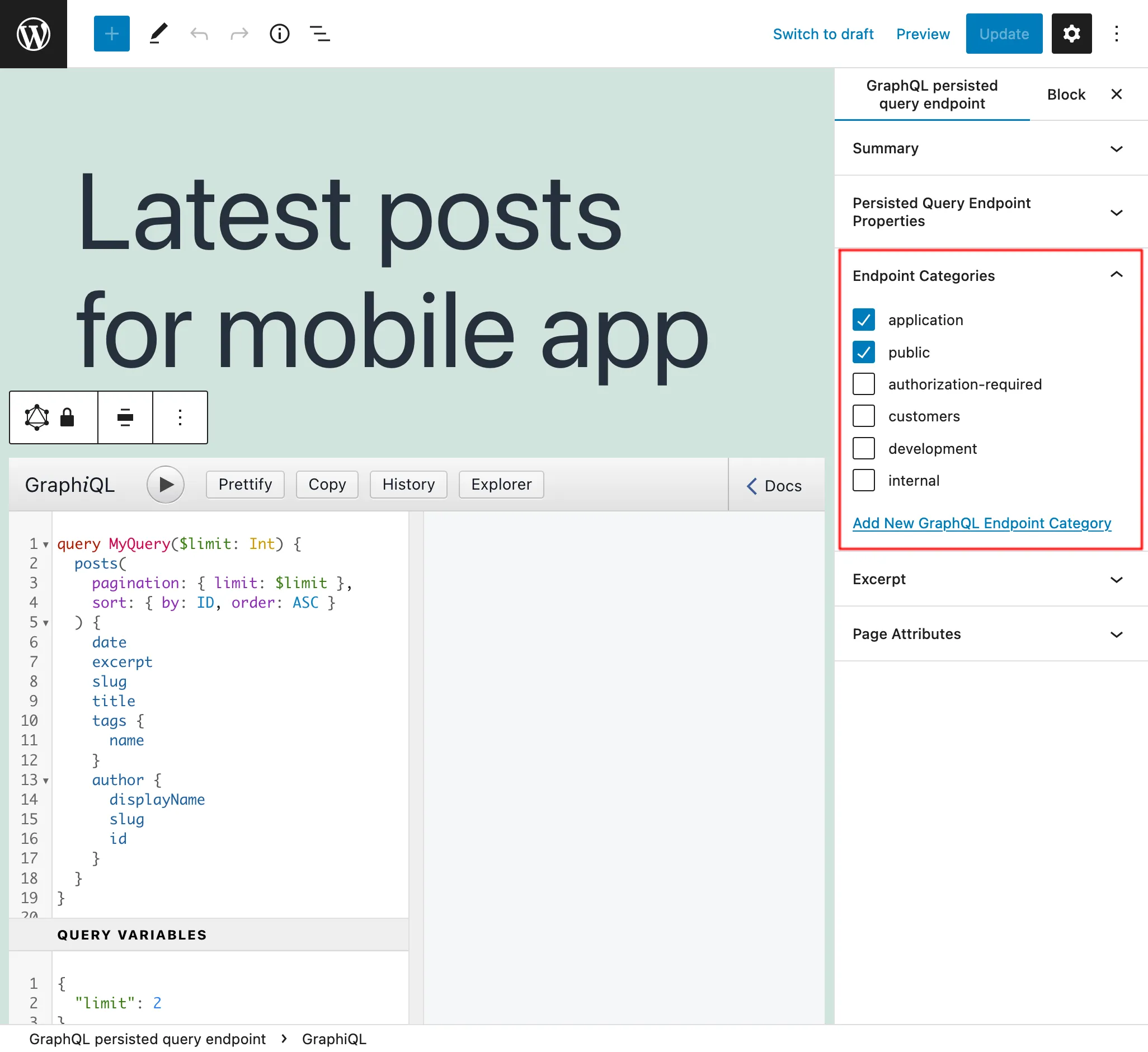
Par exemple, nous pouvons créer des catégories pour gérer les endpoints par client, application, ou toute autre information nécessaire :

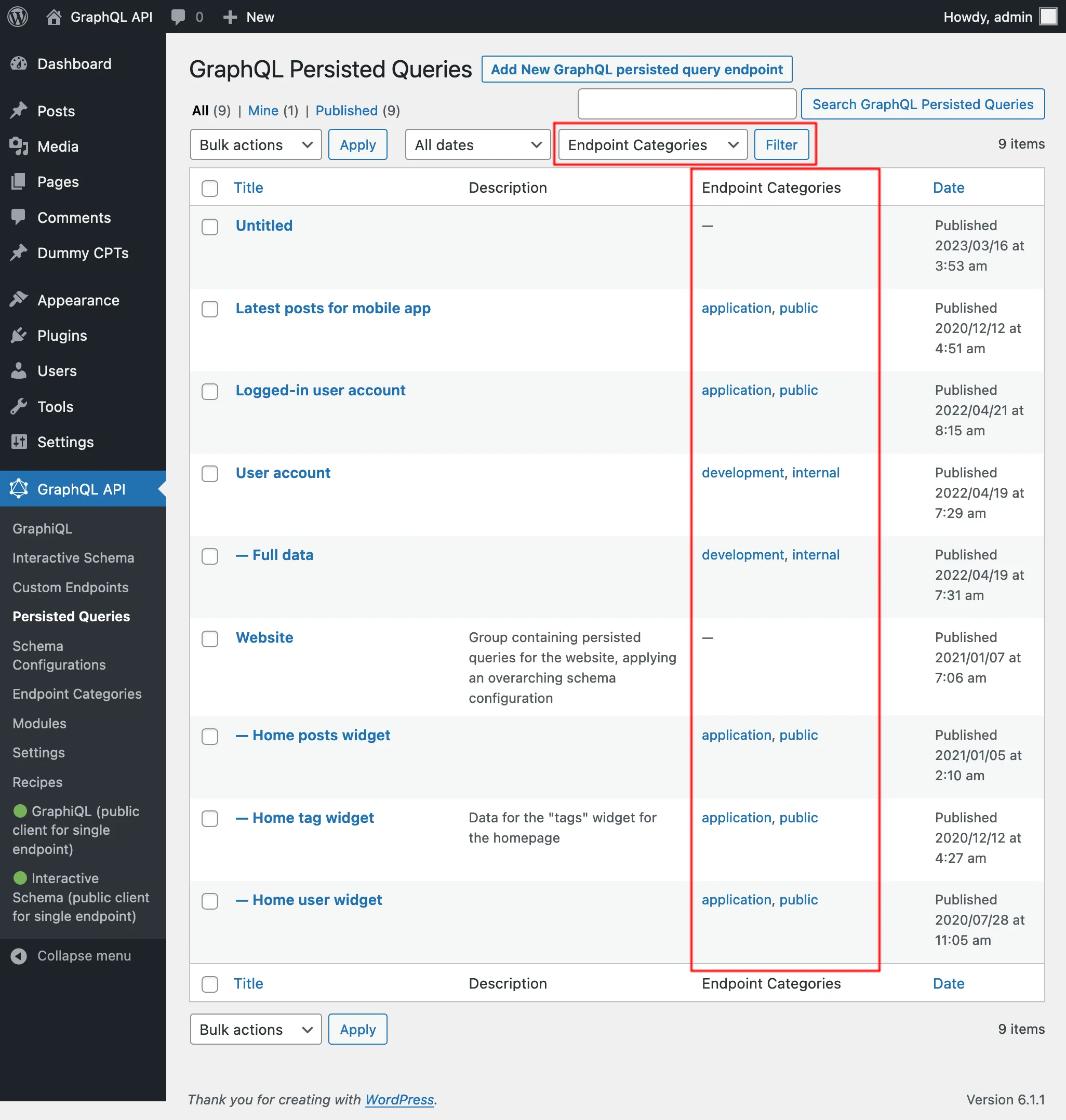
Dans la liste des Persisted Queries, nous pouvons visualiser leurs catégories et, en cliquant sur n'importe quel lien de catégorie, ou en utilisant le filtre en haut, seules les entrées de cette catégorie seront affichées :
Persisted queries privées
En définissant le statut de la Persisted Query sur private, l'endpoint ne peut être accessible que par l'administrateur. Cela évite que nos données soient partagées involontairement avec des utilisateurs qui ne devraient pas y avoir accès.
Par exemple, nous pouvons créer des Persisted Queries privées pour aider à gérer l'application, comme la récupération de données pour créer des rapports avec nos métriques.
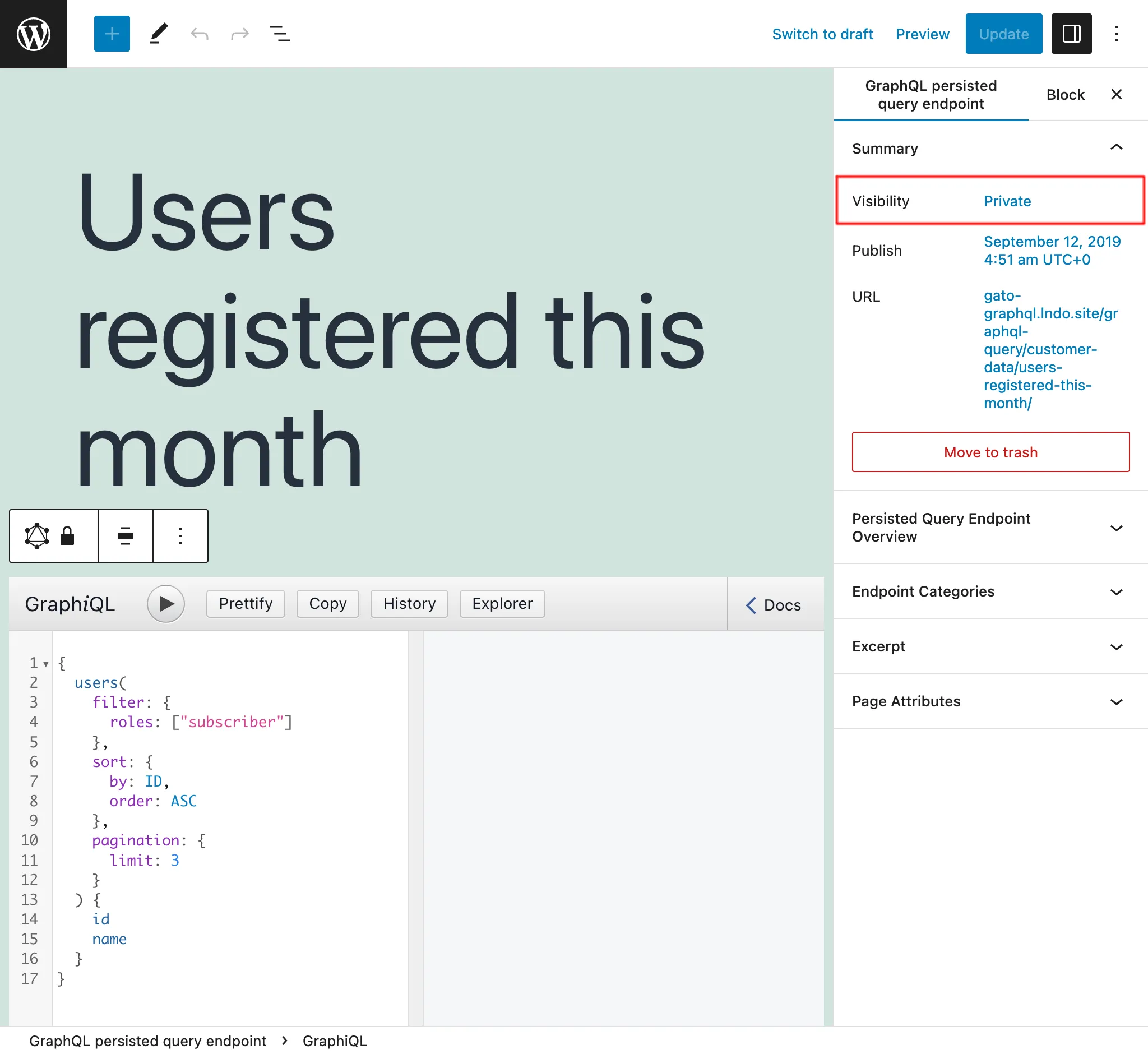
Persisted queries protégées par mot de passe
Si nous créons une Persisted Query pour un client spécifique, nous pouvons lui attribuer un mot de passe, afin de fournir un niveau de sécurité supplémentaire et que seul ce client accède à l'endpoint.
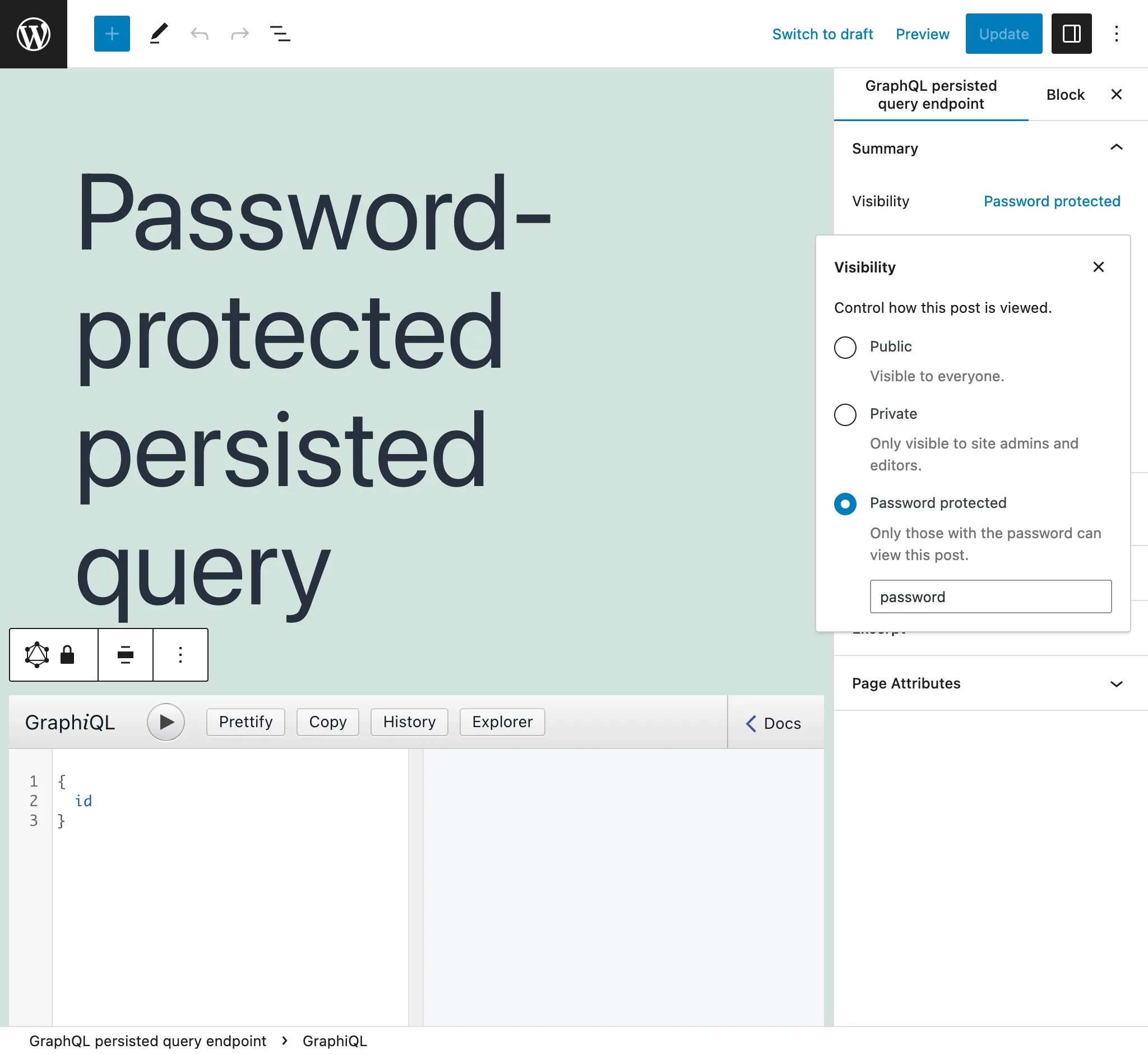
Lors du premier accès à une persisted query protégée par mot de passe, un écran demandant le mot de passe s'affiche :
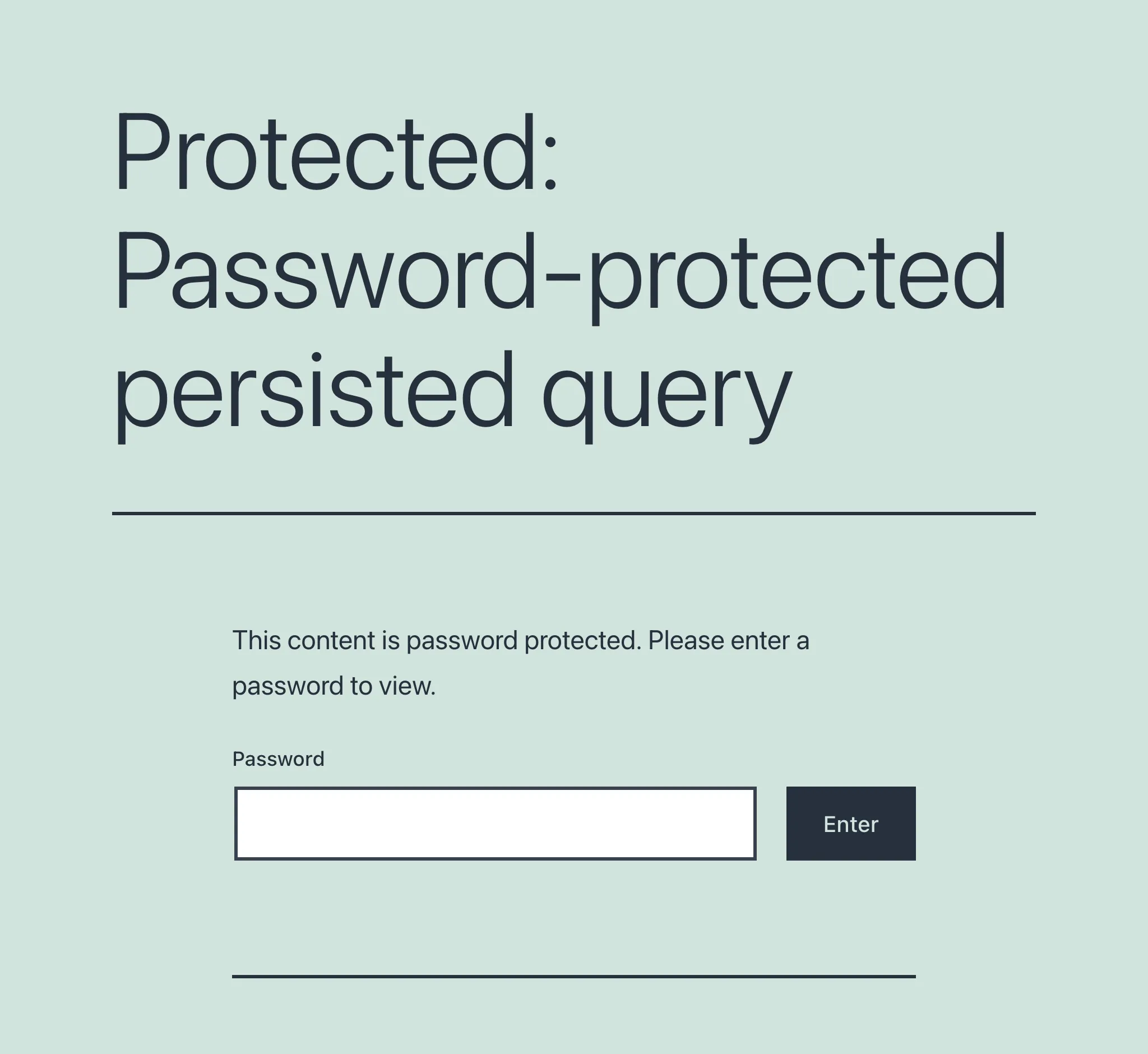
Une fois le mot de passe fourni et validé, l'utilisateur accède alors à l'endpoint prévu.
Rendre la persisted query dynamique via des paramètres URL
La valeur de chaque variable peut être définie via un paramètre URL (avec le nom de la variable) lors de l'exécution de la persisted query. Si l'option "Les paramètres URL remplacent-ils les variables ?" est activée, le paramètre URL aura la priorité. Sinon, la valeur définie dans le dictionnaire de variables aura la priorité (le cas échéant).
Par exemple, dans cette requête, le nombre de résultats est contrôlé via la variable $limit, avec une valeur par défaut de 3 :
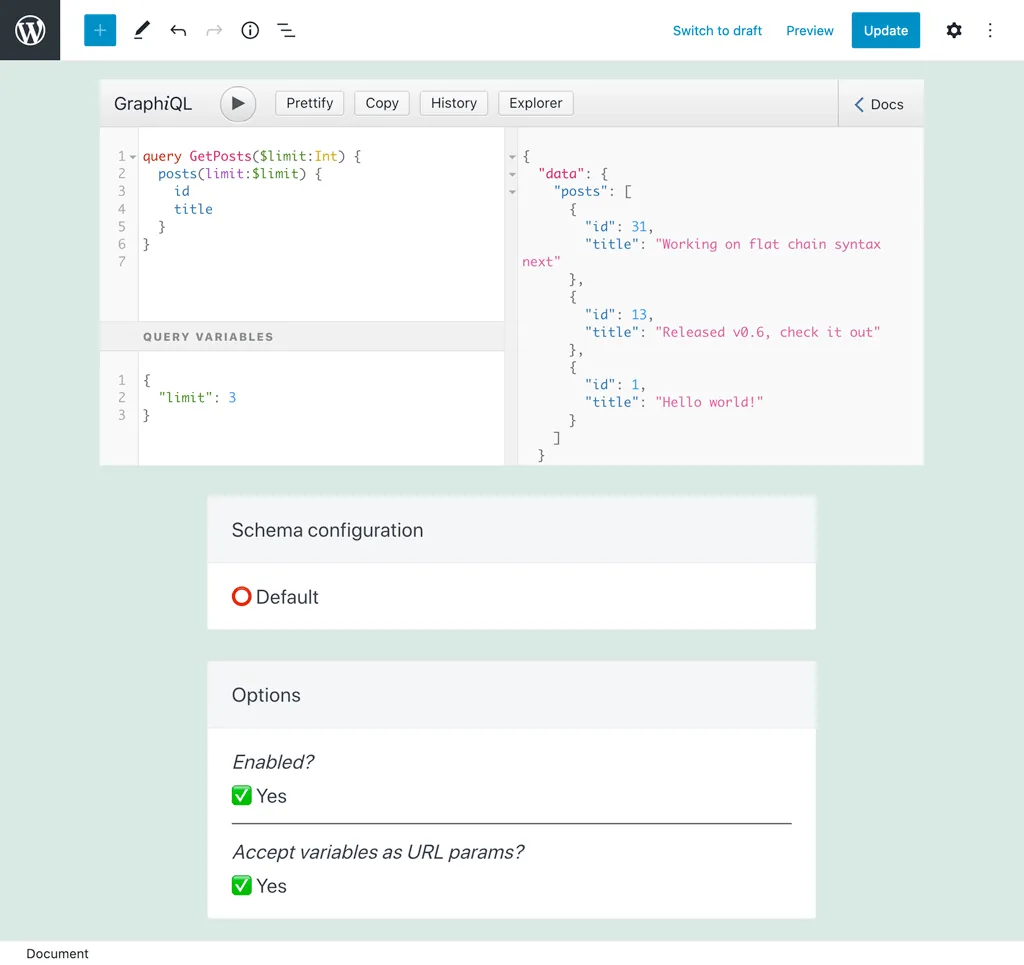
Lors de l'exécution de cette persisted query, passer ?limit=5 exécutera la requête en retournant 5 résultats à la place :